
How do you usually build an enterprise application?
I find it common throughout my career to start with database design. It seems to make sense since we are storing and retrieving data from the system after all. Moreover, it is usually coupled with layered architecture; this is perhaps the most widely used application architecture in the tech industry. Almost all software engineers are at least familiar with working with it. Let me show you how it looks.

This architecture is pretty standard. We essentially divide the application into three layers (e.g., User Interface, Business Logic Layer, Data Access Layer), each layer having its distinct responsibility, as shown above.
But I want to focus on the flow of dependencies between these layers, which flows from top to bottom.
Let’s take a deeper look in terms of implementation. Since the data access layer cannot know anything about the business logic layer, the only way the application can successfully put data into the database is for the business logic layer to contain the logic to convert the business record into the database format accordingly.
It now introduces tight coupling between these two layers. The business logic layer directly manipulates the database model.
If we wish to change our database (e.g., SQL to NoSQL), the business logic layer will need to undergo significant code change.
Although changing between database vendors may be rare in practice, what is perhaps not uncommon would be improving the database performance. Improving database performance may require us to modify our database model (e.g., denormalizing tables), leading to a high risk of system regression because of tight coupling.
That is why layered architecture is known to be database-centric. We typically start with designing the database and work our way up. Don’t get me wrong. Layered architecture is not all bad. It is still helpful for CRUD applications and onboarding a new member quickly. But when it comes to more complex enterprise applications, I suggest considering Clean Architecture.
What is Clean Architecture?
Clean architecture pushes the database off the center and replaces it with the domain, making it a domain-centric architecture. Design and development can now occur without thinking in terms of the database models. The domain model can now freely evolve without being coupled to the database.
How does clean architecture accomplish this? Let me show you a diagram.
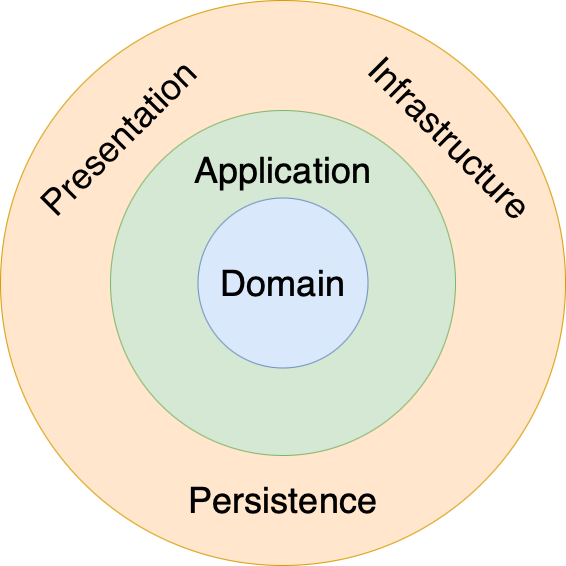
Dependency Rule
Clean architecture is usually depicted as a set of concentric circles. The dominant rule of this architecture is the flow of dependency point inwards. Inner layers should not know anything about outer layers, but only the latter knows the former.
But we know that the natural flow of control between the application and persistence layer is towards the latter; this makes the natural flow of dependency follow in the same direction. However, the architecture can invert the dependency flow by using a technique called dependency inversion.
The application layer can invert the dependency flow by exposing an interface to the persistence layer. It will call the interface as necessary without knowing the implementation detail, leaving it to the persistence layer to define. That enables the application core to focus on what is more important, the business rules, and be free from external frameworks and dependencies.
Advantages
By adopting clean architecture, we achieve a loosely coupled codebase. We can freely modify our database models to improve performance without making any changes to the business logic layer. Another advantage is it allows us to easily swap different user interfaces (e.g., REST and MVC adapters).
Example
If you are interested to see an example, I have designed and implemented a parking lot system using clean architecture. Please feel free to browse and check my work.
I hope this short blog post helps you in some way!
Happy coding!